背景
Softmax由于其每个分类正负样本的概率是对称的,使得其类内不够紧凑,针对这一缺点各种文章百花齐放,各种小修小改,其关键目的就是提高inter-class dispension和intra-class compactness.对于close-set的人脸识别任务,现有的分类手段已经能够做得比较好了,但是对于open-set的人脸识别任务,就要求即使是不在训练集里面的人脸,也应该要将同一个人的脸的feature映射到特征空间里一个紧凑的位置从而使得无监督的聚类算法可以介入。这里有一个基本的要求,就是类内的最大距离一定不能大于类间的最小距离,部分文章还额外加上一个margin,也就是类内的最大距离要小于类间的最小距离减去margin,也就是还得留出一定的隔离带。这个要求也被大部分的Siamese类network所接受。open-set的人脸识别实际上是一种metric learning, 学的关键就是这个feature,而不是后面的classifier
下面我们来看看基于改进softmax的每一家具体的方案。
注意:以下的x是需要学习的样本的特征表示,是要学习的目的之一啊,不是固定的,我们要学的就是一个可以无监督分类的x,所谓metric learning, 可以理解为固定W学习x然后固定x计算新的W,W对应FC层的权重,x则是这之前的神经网络提取的特征,Wx一般输入到Softmax中,下面的所有推导中,都假设当前W固定,下一步是优化x,并说明为啥这些改动会使得得到的x更加紧凑
CenterLoss (ECCV2016)
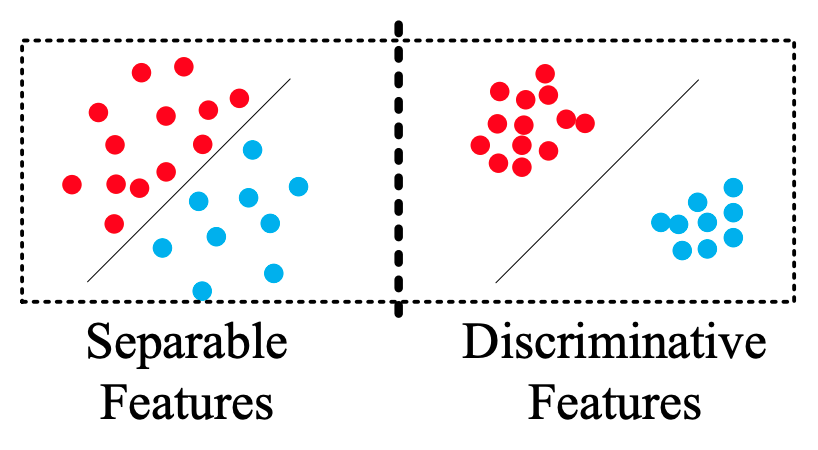
这是由 https://kpzhang93.github.io/papers/eccv2016.pdf (A Discriminative Feature Learning Approach for Deep Face Recognition)这篇文章提出的。并且这样类似的方法并不只此一家,softmax + 某种能够强调类内compactness的loss都可以,比如softmax + tripletloss(不实用,好难设计样本对,exmaple mining不好做,训练时直接一步loss为0欠拟合是喜闻乐见的)等等。毕竟属于社会主义初级阶段,依然还是loss之间的排列组合。这篇文章还澄清了一对很重要的概念,那就是separable features和discriminative feature。separable feature可以理解为神经网络fc前最后一层,是线性可分的。而discriminative则不仅要separable,还必须保持类内紧凑,从而方便最近邻聚类等算法进行聚类,以保持对未知类别的可分性。换句话说,给一个不在训练集里面的人脸的多个样本,输出的feature不仅要和库里面的不同,并且这几个额外的样本在特征空间里面是要聚成一团的,可以无监督地得出这是一个新的类别。这样子就使得人脸识别模型在新来一个人的脸后不需要重新进行训练。从close-set的识别能力扩展到了open-set。
正如其名字所表示的那样,center loss在每一个batch中,对每一类的所有样本的feature算了一个均值,然后损失函数为原softmax(类间差异)+center loss(类内紧凑)。
这篇文章开了一个类内紧凑的头,但是缺点是 每个batch都得要预先算一个中心,每个batch中心又是在不断改变的,这就导致了不一定会收敛(实际上作者将centor loss的权重调的比较小所以这个问题在实验中并没有体现出来。
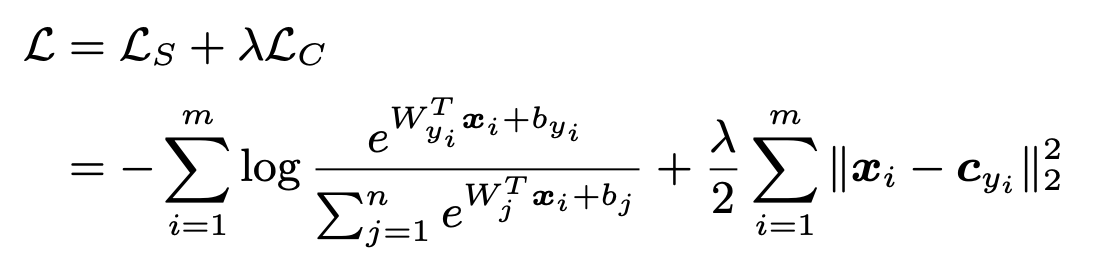
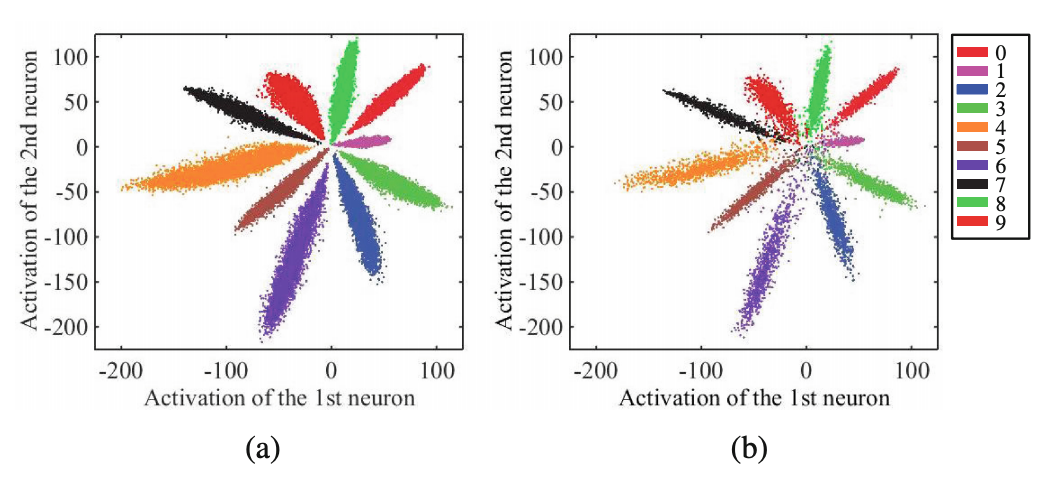
这篇文章还有一个副产物,那就是发现softmax的结果总是天然地按照弧度扇形分布,这个结果被后续的文章所使用,并产生了angular margin这么一个新的热词。
SphereFace (CVPR2017)
https://arxiv.org/pdf/1704.08063.pdf
首次提出angular margin,不再是之前画个二维散点图然后用直线区分几个分类的那种(Euclidean margin,比如SVM),现在它将样本看做是分布在圆弧(二维)或者高维球面上的点,根据圆(球)心角来区分几个不同的分类。
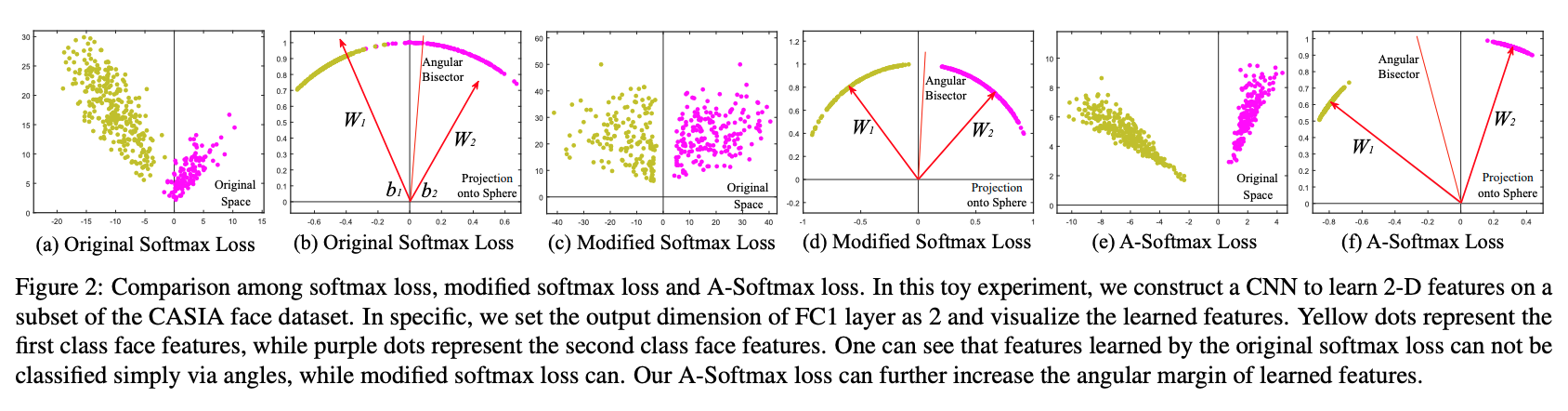
第一阶段 Modified-Softmax也是初步的A-Softmax
作者提出,softmax的结果虽然很像可以按角度去进行区分,实际上却又不是那么简单(比如上图a在不限制$W$的模长的情况下,样本在特征空间上的分布是不均匀的),于是需要对softmax进行一些修改。
为了方便说明,这里以二分类为例,对于原始softmax, 两个类的分界线可以写成:
这就是softmax上面的幂指数相等的那个线。在原始的softmax函数中,两个W的模能够对分界线有较大的影响,想象到极限情况下,$\lVert W_1\rVert=+\infty,\lVert W_2\rVert=0$,这时候符合第一类的样本只需要满足$W_1x>0$,bias此时已经变得不重要了。这个条件此时是非常容易满足的,只要不是完全和$W_1$正交就好,也就是$W_1$这边x的空间会摊得非常大,而$W_2$这边就被压缩的几乎看不到了,图b能够稍微看到一些这样的迹象,但是不准确。当然,一个正常训练的样本均衡的模型实际上并不会出现这样的$W$。如图b所示,两个向量的中间位置的夹角,并不能够区分两类样本(稍微调整下位置还是可以的),也就是,这个中心,还不够‘中心’,因为组成这个中心的两边是不平衡的。中心不平衡带来的问题就是,从$W_1$到$W_2$这个扇形里面,每一个单位弧度所包含的样本概率密度是不一样的,靠近$W_1$这边,由于$W_1$的模较大,其对应的同角度的x的模长范围就限制得比较松,或者同等模长的$x$则可以取值的角度范围较大,此时的实际分界线是偏向于模长较短的$W_2$这边的(即留给$W_1$更多位置),而不是图b中的二分位置。有问题吗?没问题,只是没必要这样而已,如果能够限制两$W$的模长一致,那么就不需要算这个实际的分界点了,直接就是$(W_1+W_2)/2$,也就是角平分线就可以了。
为了方便,假如我们限制$\lVert W_1\rVert = \lVert W_2\rVert$,且$b_1=b_2=0$,那么我们有这样的分界线:
这时候学习到的样本空间就能够很好地由角度分开了(毕竟现在就是在直接优化$\theta$啊,能学不到嘛。。。实际上是优化x和W来达到优化$\theta$的目的),对应上图d。至此,我们已经能够用angular来替代euclidean softmax了,但是仅仅是替代,依然还没解决类内不紧凑的问题。
第二阶段 增加类内紧凑性后的A-Softmax
为了进一步分开两类,显然像SVM一样引入一块间隔margin能够增加模型的鲁棒性。这块margin中的样本不会被判断为任何一个类,实际上模型学习到的feature不会映射到这个区间内。看图f,在没有引入m之前,中间的Angular Bisector就是两类的分界线,在分界线的左边,以$W_1$为中心,越往两边其被分为第一类的置信度就越低,在分界线附近分为任何一类的置信度就一样了。要引入一个间隔,实际上就是以angular bisector为中心,在附近引入一块区域,特征落在这块区域中时,既不是第一类,也不是第二类。压缩的办法比较粗暴,那就是在bisector左边压缩$\theta_1$,而在右边压缩$\theta_2$,以左侧为例,引入下式作为判断类1的分界点:
右侧判断类2的则相应的是:
看左边对应的公式,这条式子的特别之处就是$\theta_2$是不变的,而使用$m\theta_1$来整体替代之前的$\theta_1$,$m$是一个大于1的数值,这就会压缩$\theta_1$的取值范围,又不影响$\theta_2$,如果此时$\theta_1$靠近bisector附近,那么$\lVert x\rVert (cos(m\theta_1)-cos(\theta_2))<0$, 此时该样本不能被判为类1.同理用一样的方法对另一边进行操作,也会压缩另一个类2的取值范围,类2也会出现一个区域不能被判为2,这段既不能为1也不能为2的区域就组成了我们要的margin.训练过程中落在这些区域的样本由于被梯度往左右两边(拉向$W_1, W_2$)时loss会更少,因此充分训练后,可分的样本都不会出现在这个区域中。
CosFace
cosface的想法也是比较类似的,但是m放的位置不同,它采用的是:
注意这个减号,因为cos在$[0, \pi]$之间是单调递减的,这个作用大致也是相当于往$\theta$乘上一个大于1的数,来压缩相应边$\theta$的取值范围。
ArcFace
https://arxiv.org/pdf/1801.07698.pdf
一样的配方,m放在了cos里面,间隔改成了:
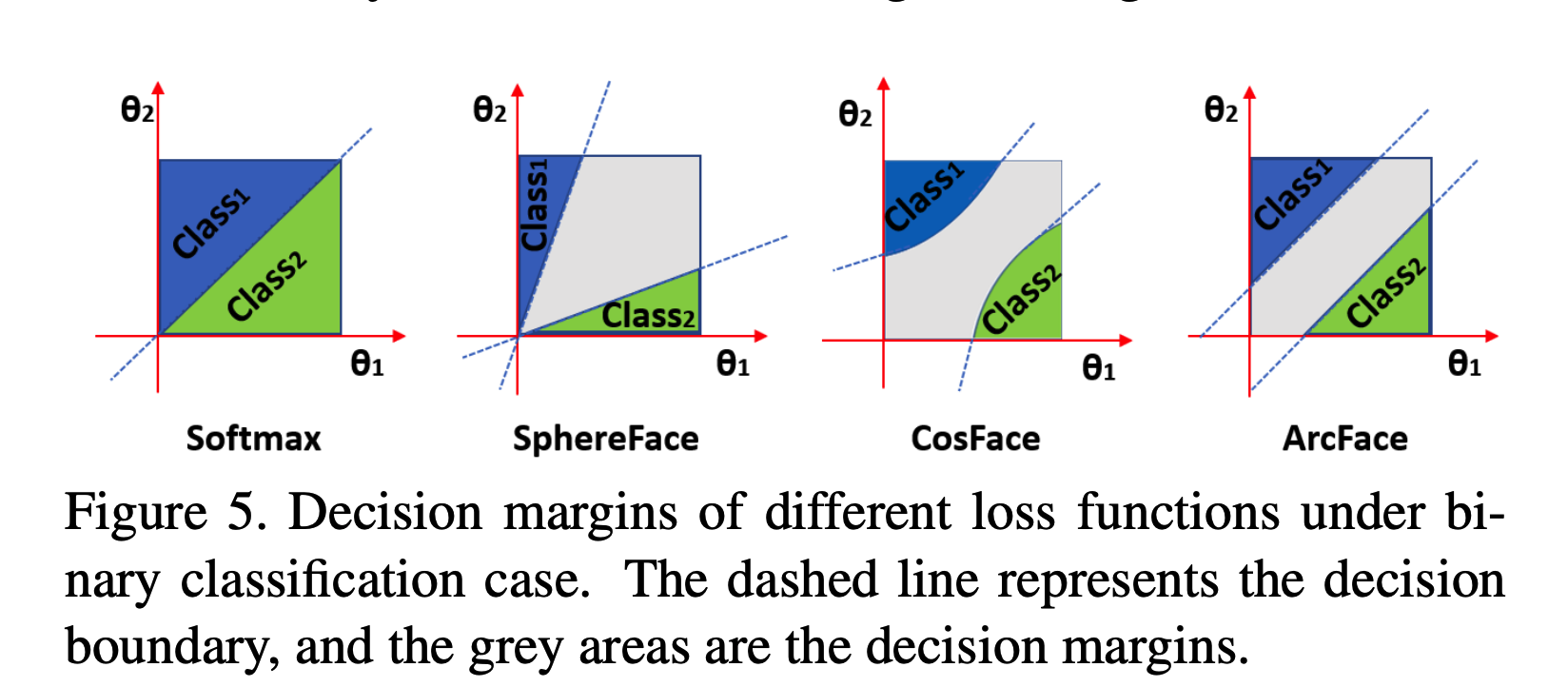
几种Loss的区别
ArcFace里面详细分析了几种修补版softmax的区别,并指出只有ArcFace这种方式能够保持间隔在每个$\theta_1, \theta_2$保持一致。