Scrapy框架介绍
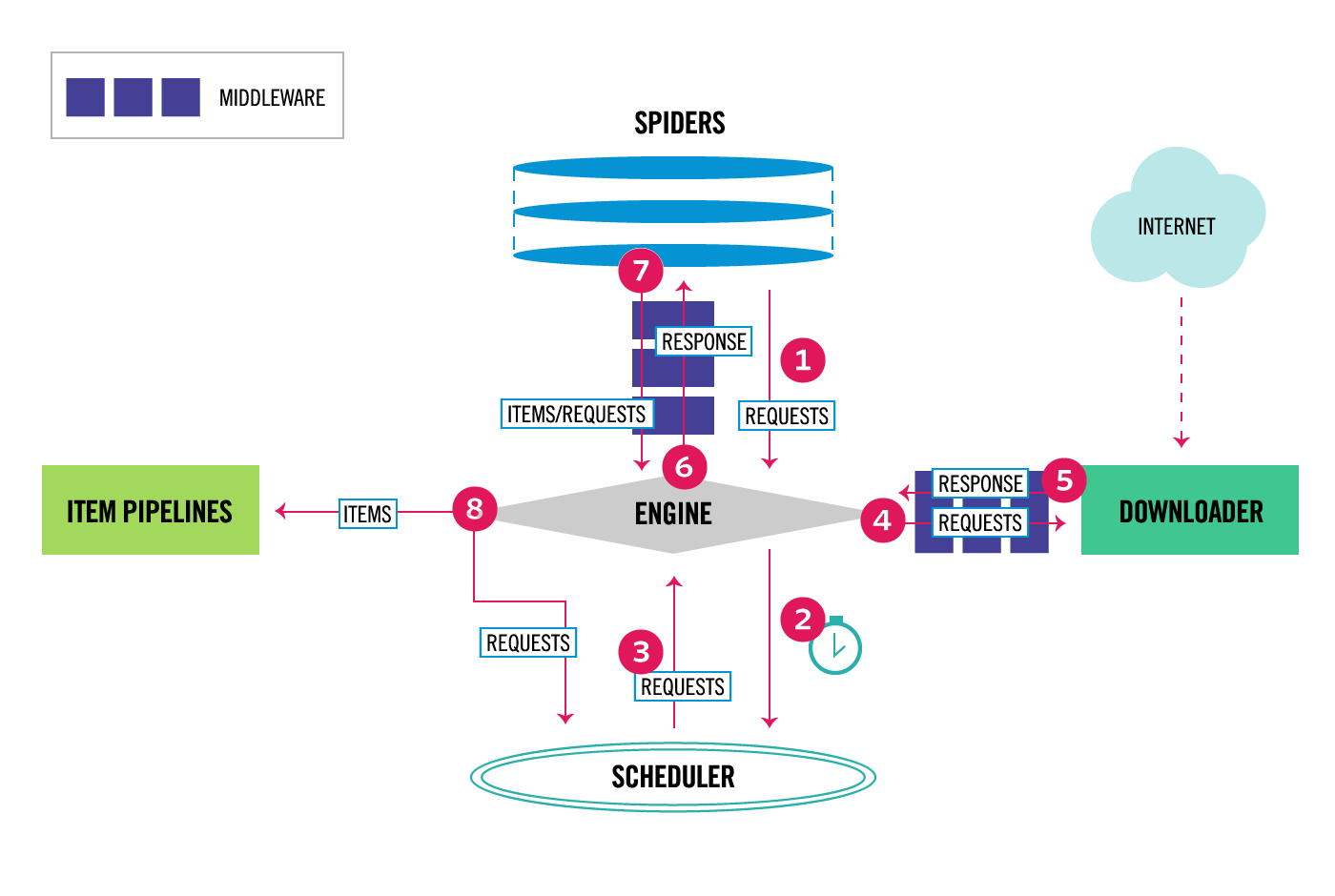
scrapy作为一种可以轻易扩展为分布式的爬虫框架,其内部框架采用类似于消息队列的方式进行任务的调度分发也就不奇怪了,消息队列使得各组件低耦合。至于这个消息队列是存在于单机内存中还是分布式集群中的一个节点,就看业务的需要了。采用生产者-消费者模式进行组织的系统实际上就是三块:任务的生产者,消费者以及消息队列。对应框架图上:
生产者:Spiders
消费者:Downloader
消息队列:Scheduler以及Engine
各部分组件由Engine进行驱动,Engine可以看做是一个main函数吧。生产者生产任务(在这里就是要爬取的url)放到消息队列,消费者从消息队列中取得任务进行实际的下载。下载结果交给生产者进行解析,解析结果的一部分是我们要提取的信息,它直接进入Pipeline进行处理,另一部分则是从下载结果中提取的新的任务(url),它将进入消息队列中。整个流程是:
- (1)一开始Scheduler的队列是空的,所以需要人工hard code一个起始的种子url列表,spider将这些url封装成Request,Engine将这些Request转给Scheduler
- (2)与此同时,一旦Scheduler队列非空,Engine将从Scheduler中抽取一个Request给Downloader进行实际下载,Downloader的产出即Response由engine转给spider
- (3)Spider抽取Response里面两类信息:第一类就是页面上我们实际要爬取的内容Item,以及这个页面包含的符合要求的url列表。Item由Engine转入Item的深层加工流水线Pipeline,进行进一步的筛选、存储等, url由Spider封装为Request经由Engine交给Scheduler。重复(2)
框架图中engine和各组件交换Request和Response的过程中可以插入各种额外的流程,称之为中间件,所以不难想象一共有两种种中间件:Downloader middlewares(对应图中4,5)和 Spider middlewares(对应图中6,7)。除此之外,Item Pipeline中可以插入处理Item的各个步骤。工程框架
我们以爬取google play上面apk应用的信息为例。
安装完scrapy后,可以采用scrapy startproject gglplay来创建一个叫做gglplay的爬虫工程,其结构如下: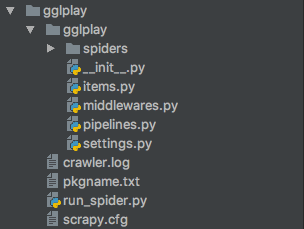
项目框架
其中settings.py类似于一种静态配置文件,所有增加的中间件以及pipeline等都需要在settings中进行注册,类似于Android的manifest这样的角色。run_spider.py是人工添加进去的,下面会说到。
Spider
首先,创建的项目中是没有默认Spider的,需要手工新建一个Spider类,继承scrapy.Spider或它的子类。也可以采用scrapy genspider [-t template] <name> <domain> 来根据模板生成一个spider。 所有新增的Spider都需要放在spider文件夹下。
- name变量
每一个Spider的关键变量就是 name, 在启动的时候通过name来搜索这个spider。比如说scrapy crawl gglplay就启动了一个name='gglplay'的爬虫。新增爬虫无需更新settings,只需要保证每个Spider都有唯一的name就好了。 - allow_domains
爬虫允许爬取的域 - start_urls
如上面所介绍,就是起始的url,种子url - rule
定义url匹配了某个规则后,用什么样的parse函数进行内容提取。比如说:Rule(LinkExtractor(allow=(“/store/apps/details”,)), callback=’parse_app’, follow=True)就定义了一旦LinkExtractor获得了匹配的url,那么对这个url进行下载后的内容将由parse_app这一个回调函数进行处理。这样子就能使得每个不同的页面,对应不同的parse函数,不会说要一个parse函数去处理所有的页面,毕竟格式不同,xpath不同,所需的信息也不同。Middlewares
Middleware分为Downloader middlewares和Spider middlewares。但是需要注意的是,Middleware需要在setting进行注册,定义middleware的处理顺序。
Spider middlewares
Spider middlewares在Spider的输入和输出做文章,所以关键的两个钩子就是process_spider_input和process_spider_output,都是顾名思义的了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class GglplaySpiderMiddleware(object):
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
# if result['package'] not in spider.bf:
# spider.bf.add(result['package'])
# yield i
# else:
# continue
yield i
在settings中的注册语句:1
2
3SPIDER_MIDDLEWARES = {
'gglplay.middlewares.GglplaySpiderMiddleware': 543,
}
关于Spider Middleware,详细可以看http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
Downloader Middleware
Downloader Middleware和Spider Middleware几乎一样,详细可以看:
http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
Item Pipeline
一般在Item Pipeline中进行item的筛选,持久化存储等工作,如果Pipeline中某个item被认定为需要丢弃,可以通过raise DropItem来发起,该Item就不会再经过后续的pipeline。定义好pipeline后还需要在settings中定义他们的顺序,比如:1
2
3
4ITEM_PIPELINES = {
'gglplay.pipelines.GglplayPipeline': 300,
'gglplay.pipelines.StoreItemPipeline': 400,
}
定义了两个模块的处理流程,item先经过gglplay.pipelines.GglplayPipeline,再经过gglplay.pipelines.StoreItemPipeline,注意到数字越小,处理优先级越高。
详细可以看:http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
运行脚本
直接命令行scrapy crawl的方式难以调试,为了方便调试,我们可以在项目顶层建立一个driver,这样子在pycharm之类的IDE中就能够比较方便进行断点调试了。
run_spider.py内容如下:1
2
3
4
5
6
7if __name__ == "__main__":
# TODO: do something here
from scrapy import cmdline
name = 'gglplay'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
pass
整个项目放置在(private, 仅作者可见):
https://github.com/ruanmk/google-play-crawler