导言
快速过一遍计算机视觉中用到的网络结构的名词描述。
- Inception V1-V3
Inception结构
InceptionV1 https://zhuanlan.zhihu.com/p/30756181
InceptionV2 + InceptionV3 https://arxiv.org/pdf/1512.00567.pdf
设计思想
主要来自InceptionV2V3的论文: https://arxiv.org/pdf/1512.00567.pdf
Avoid representational bottlenecks, especially early in the network. Feed-forward networks can be represented by an acyclic graph from the input layer(s) to the classifier or regressor. This defines a clear direction for the information flow. For any cut separating the inputs from the outputs, one can access the amount of information passing though the cut. One should avoid
bottlenecks with extreme compression. In general the representation size should gently decrease from the inputs to the outputs before reaching the final representation used for the task at hand. Theoretically, information content can not be assessed merely by the dimensionality of the representation as it discards important factors like correlation structure; the dimensionality merely provides a rough estimate of information content.
第一条就是不要尝试在网络早期就将网络的信息压缩到太小,被前面网络去除掉的信息是不能够被后续找回的,因为CNN是一个无环路的图。Higher dimensional representations are easier to process locally within a network. Increasing the activations per tile in a convolutional network allows for more disentangled features. The resulting networks will train faster.
第二条的意思就是,更加高维的输入会更加方便寻找local feature, 也就是更加方便cnn来获得局部特征,因此神经网络的激活神经元应该高一些,保留的激活部分多一些,而不是压抑激活单元。Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power. For example, before performing a more spread out (e.g. 3 × 3) convolution, one can reduce the dimension of the input representation before the spatial aggregation without expecting serious adverse effects. We hypothesize that the reason for that is the strong correlation between adjacent unit results in much less loss of information during dimension reduction, if the outputs are used in a spatial aggregation context. Given that these signals should be easily compressible, the dimension reduction even promotes faster learning.
第三条说的是,在底层的特征可以先压缩再进行卷积,并不会影响到最终的效果,这个假设成立的前提就是,上一层的神经网络输出存在相关性,允许被压缩。注意到这条和第一条是稍微有一些相反的,第一条建议的是不要过快进行信息的压缩,而这里提出的是可以先进行1x1压缩再进行卷积是不会对最终结果有太大影响。这里的度就是玄学所在了。Balance the width and depth of the network. Optimal performance of the network can be reached by balancing the number of filters per stage and the depth of the network. Increasing both the width and the depth of the network can contribute to higher quality networks. However, the optimal improvement for a constant amount of computation can be reached if both are
increased in parallel. The computational budget should therefore be distributed in a balanced way between the depth and width of the network.
第四条就更玄学了,增加网络的宽(每层更多的filter)和深(更深的网络,少用stride)都能够提高网络的表达能力,但是特定的计算能力预算下,怎样分配宽和深是一个不容易,甚至是玄学的事情。唔,道理都懂…其实有没有人想过为什么CNN一层一层垒在一起就能够有这么强的表达能力?
Inception系列网络
Inception系列网络可以参考这个链接: https://zhuanlan.zhihu.com/p/30756181
Inception是一种常见的模块,其作用是在同一层获得不同scale的卷积结果。scale在物体检测领域是非常重要的一个参数,设计再良好的特征,如果scale不对也很难获得好的检测结果,当前基于RPN或者基于Anchor的two-stage detection主要也是致力于解决scale问题,因为数据刷到现在,难点一般都是对小的物体存在大量的漏检,而增强对小物体的检测能力(recall)一般又会伴随而来是大量的误检(FP)。
Inception系列网络最主要的思想就是在同一层卷积神经网络里面并行多个卷积核,并将卷积结果concat起来,从而在同一层中就能够获得不同感受野的feature map。
第一代GoogleNet提出InceptionV1
论文来自: https://arxiv.org/pdf/1409.4842.pdf
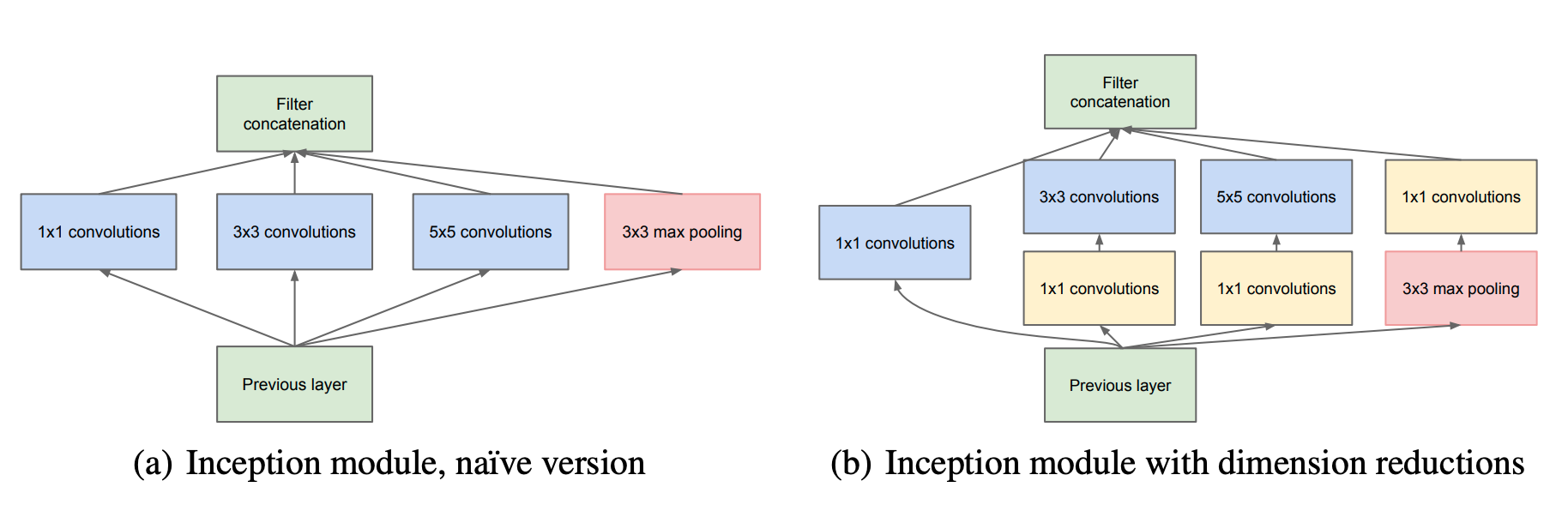
图1
为什么能够用1x1来进行channel数量的缩减,因为存在这样的一个假设,在神经网络最后的输出层里面,feature map有多个部分是高度相关的,可以按照相关性分为多个组,每个组可以认为是抓住了原图像中特定的区域或者特定的特征,换句话说,信息存在冗余,这是可以用1x1来进行reduce的理论基础。
同样的,文章认为,这些相关组有些cover的区域比较小,有些比较大,这就要求同一层同scale的卷积应该有多种卷积核,至于为什么采用3x3 5x5并不是因为经过精确计算这些大小的核符合要求,而是因为方便和常用,有现成的实现。
由于高层网络更应该抓住高层信息,因此论文建议,越高的层,其3x3, 5x5的卷积核应该相应地增多。当然,实际上并没有这么做,因为会额外增加网络设计的复杂性,同时这个也是非常heuristic的想法,需要手工进行设置。
有人会比较好奇,3x3, 5x5之后的结果怎样进行concate,大小不是不一致的吗,其实主要是通过对原图padding然后进行convolution得到的,比如3x3比5x5输出feature map大小是要大2的,只需要让5x5padding为1(两边共补2)就可以了。
看这个tensorflow实现的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
class Inception(nn.Block):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu')
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu')
self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1,
activation='relu')
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu')
self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2,
activation='relu')
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1)
self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu')
def forward(self, x):
p1 = self.p1_1(x)
p2 = self.p2_2(self.p2_1(x))
p3 = self.p3_2(self.p3_1(x))
p4 = self.p4_2(self.p4_1(x))
return nd.concat(p1, p2, p3, p4, dim=1) # 在通道维上连结输出
其中1x1, 3x3, 5x5分别pad 0, 1, 2个像素,来使得输出和输入大小一致。
Inception V2
- 在V1基础上,添加了Batch Norm
- 用两个3x3代替一个5x5, 参数量减少,同时增加了网络的深度,计算到的感受野却没有改变。
- 作者想,那能不能用2x2或者更小的卷积核来替代大核呢,于是,极端地,作者认为可以用1xn和nx1的组合来替代一个nxn的大核。这样的替代在中层(输入大小从12到20部分)是有效的,但是不能够被用于底层,也就是一开始几层。原因没有进一步说明。用1xn和nx1来替代n x n, 同样减少参数,同时增加了网络深度。实验证明,在中间层网络,用1x7和7x1的效果不错。(玄学)
- 增加输出的channel数量(原则2),如下图所示,将3x3拆成1x3和3x1两个平行的channel(注意不是串联),从而保留高维的表达。
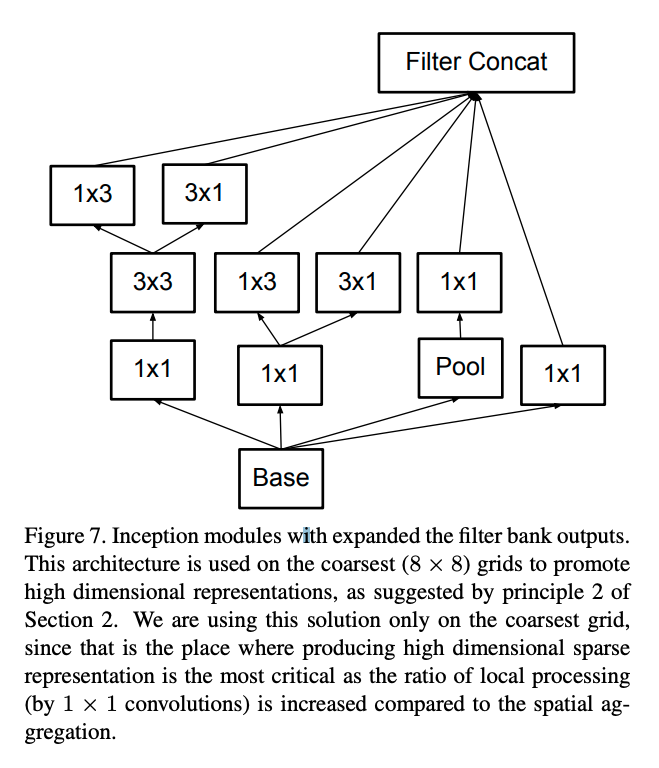
图2
- 可以使用并行结构来优化Pooling。前面的规则1提到Pooling会造成represtation bottleneck,一种解决办法就是在Pooling前用1x1卷积把特征数加倍(见图3右侧),这种加倍可以理解加入了冗余的特征,然后再作Pooling就只是把冗余的信息重新去掉,没有减少信息量。这种方法有很好的效果但因为加入了1x1卷积会极大的增大 计算量。替代的方法是使用两个并行的支路,一路1x1卷积,由于特征维度没有加倍计算量相比之前减少了一倍,一路是Pooling,最后再在特征维度拼合到一起(见图4右)。这种方法即有很好的效果,又没有增大计算量。

图3
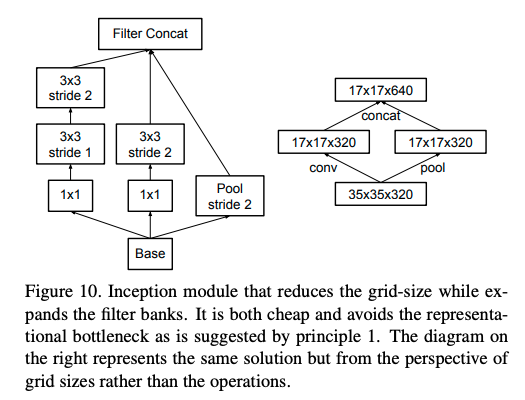
图4
Inception V3
Inception V2 + 辅助的分类器就变成了v3。 这个新的思想就是使用一个分类器来筛选有用的梯度,使得有效信息能够传回到底层网络,避免梯度消失等情况。这个相当于早期的监督信息,这个输出层插在网络的中间,可以理解为将梯度回传的起始点设置在了中间,辅助整体的学习。FPN系列也用了类似的思想。
Inception V4
https://arxiv.org/pdf/1602.07261.pdf
在此基础上,添加stem模块,Inception A, B, C, Reduction A, B等。 Reduction主要的区别就是不是直接pool为2,而是分了几个分支做stride为2的conv。实际上感觉没有InceptionV2, V3那样的比较根本性的创新。
残差系列结构
Resnet残差结构是神经网络另外一个神仙操作,可以较好地解决梯度消失等困难。
使用残差结构的比较经典的论文有ResNet, DenseNet和SENet等。
Resnet
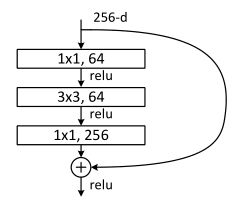
ResNet的一个重大创新设计就是这个Residual block。当然还有一个比较出名的就是其channel先减后增的bottleneck结构。
DenseNet
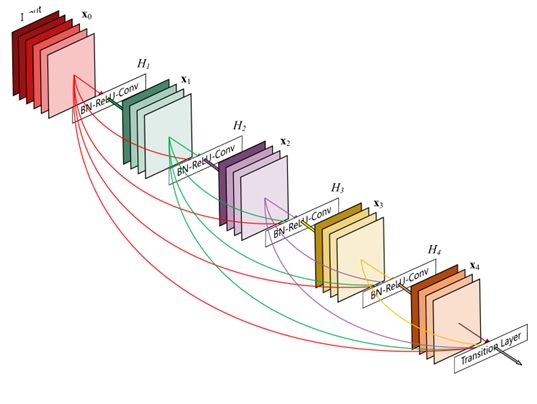
Dense就是将残差进行到底的一个网络结构。
- 使用DenseBlock,每一个block的输出都会直接输入到后面的每一个Block
- DenseBlock之间加入过渡层(Transition Layer)来结合不同大小的feature map,实质就是1x1卷积和一个stride>1的pooling操作, 当然作者选择了stride=2
Attention机制:Spatial and Channel Attention
Attention可以简单理解为通过某种机制算出某些feature map的权重,以强调网络的部分中间结果。
SENet
https://arxiv.org/pdf/1709.01507.pdf
Squeeze-and-Excitation Net, SE网络对每一个输出通道计算一个重要性权重加在输出feature中。这个权重是通过几层FC和激活得到的。应该也属于某种程度的channel attention.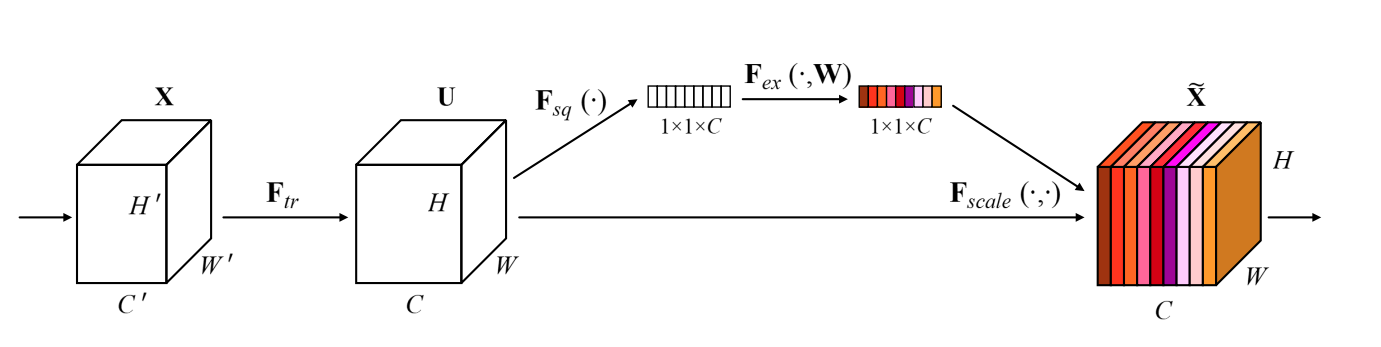
SCA-CNN
https://arxiv.org/pdf/1611.05594.pdf
CNN领域Attention的经典之作。包含channel和spatial attention.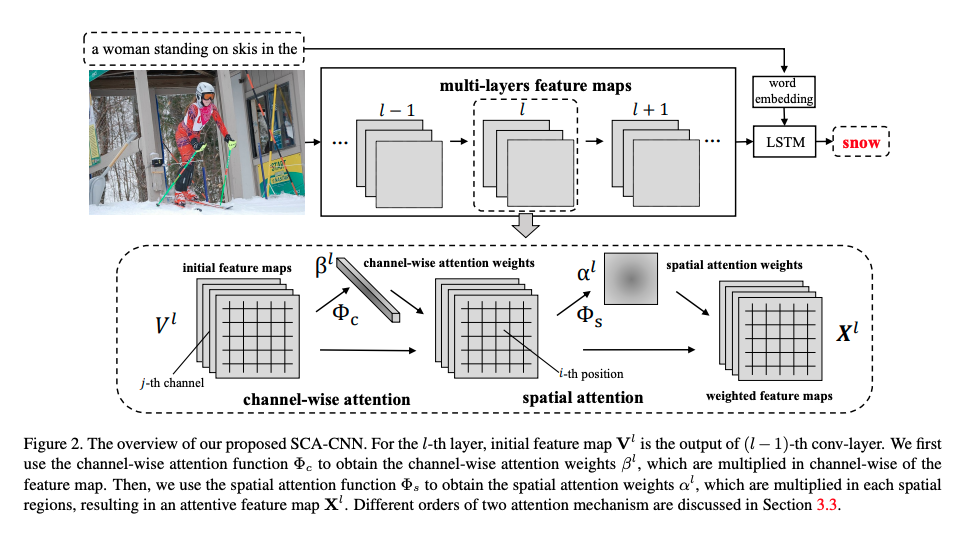
为什么说经典,因为简单。直接通过上一层或者历史feature map获得当前层的channel权重和每个位置的权重,然后将权重应用在当前层的卷积结果中。根据channel attention和spatial attention的应用先后,分成S-C和C-S模式,实际应用差别不大。
移动端优化方面
Group Convolution
AlexNet最早提出Group Convolution, 将N个channel分成M份,分别进行卷积,然后将结果concate在一起,从而减少参数量。后续再加入了channel shuffle,把性能下降稍微解决了。
Depth-Wise Convolution: MobileNet
主要提出DepthWise Conv, 意思是,首先将上一层的feature map按channel拆开,然后首先每个channel自己单独做一次卷积,得到c个channel的卷积结果,然后做一个1x1的卷积,其实还是Inception那一套,只不过连channel这样的操作都被拆开而已。
Channel Shuffle: ShuffleNet
代表性操作: channel shuffle, 就是先把输出通道group,然后group之间按一定规律交换channel来进行卷积得到下一层的feature map.
Bottleneck
Bottleneck是一类结构,其特点就是先猛下采样再上采样,形成一种类似于瓶颈的结构。比如resnet就使用了这样的结果来减少参数量和加深网络。另外大部分的encoder-decoder在大范围上也可以称作是bottleneck。
神经网络的几大范式
Encoder-Decoder
一般用于语言翻译、语义分割、以及基于heatmap的关键点检测等,其重要特点就是encoder和decoder的网络一般是对称的,且生成结果和输入结果的大小一般一致,或等比缩放。
Hourglass
Hourglass说实在的也算是Encoder-Decoder的一种。
FPN
Feature Pyramid Network,其特点是每一层feature map都会被直接利用,直接加到下一层(残差),又或者直接用于预测结果,并将多层feature map的结果综合起来。
FPN经各大网络验证,是一种高效的提升精度的方法,可惜,用在CPU上跑实时是比较难的,BU和TD过程需要耗时太多了。
参考:
https://towardsdatascience.com/review-fpn-feature-pyramid-network-object-detection-262fc7482610
https://arxiv.org/pdf/1612.03144.pdf
操作子
Pooling
Soft Pooling, 也就是我们常说的Average Pooling
Hard Pooling, 也就是我们常说的Max Pooling
Global Pooling, 实际上就是Pooling,一般用在输出层来替代FC层,用于适配输出结果的个数。比较狠的作者还可能把一个WxH的feature map直接pool成1x1的单个数值。global pooling的好处就是不需要FC层存储那么多参数进行那么多计算,但是坏处也是显而易见那就是,精度不太好,不容易训练。
Normalization
Batch Normalization (BN)
LRN
Local Response Normalization。 ReLU neurons have unbounded activations and we need LRN to normalize that.
LRN一般是在激活、池化后进行的一中处理方法。有两种模式: accross-channel和within-channel, accross-channel就是最原始的,也就是feature每个点所在channel及其相邻多个channel之内做的,相当于做一个 local_size x 1 x 1(chw)的卷积,而withn-channel则类似于avg-pooling, 只是计算公式不一样。LRN采用的计算公式为每个点除以以下分母:
其中$\alpha$是预定义的超参数,$n$就是local_size的大小,其含义就是该点周围的值越大则每个点最后计算的值越小(所谓的神经元抑制原理)。
PS:实际感觉用处不大。
物体检测框架
为啥Two-Stage比One-Stage检测效果好,RetinaNet里面解释说,One Stage中Anchor是极其不均衡的,大量的负样本和少数的正样本混合是主要的原因,并据此提出Focal Loss. 首次超越Two Stage工作。
Yolo系列
Yolo v2 v3用到的IoU-K-means
https://lars76.github.io/object-detection/k-means-anchor-boxes/
其Kmeans算Anchor的中心的时候用的是同一个组内的anchor boxes长宽分别求平均数。
V2用了FPN?
YoLo V3
个人感觉最大的改进就是设置了三个scale的anchor,分别在不同的层进行输出,同时添加了Residual。
SSD
SSD以及RetinaNet就是所谓的堆anchor狂魔。
https://zhuanlan.zhihu.com/p/33544892
YoLo采用的是中心Anchor匹配,而SSD采用的是最大IoU匹配
未能够匹配的Anchor,如果和某个正样本IoU大于0.5, 也认为是该样本在该Anchor的正例
这里会出现一个问题就是,一个Anchor会存在非常多的负样本,但是正样本就一两个,也就是样本是及其不平衡的,这就需要使用RetinaNet中提出来的Focal Loss之类的方法来进行匹配了。或者训练时人工丢弃部分负样本Anchor。
Anchor的Size是从0.2到0.9(相对于原图),每个特征图的每个格子的anchor数量是一样的,这就造成了底层(feature map还比较大的时候)anchor数量比较多,而顶层anchor数量比较少。
传统算子
边缘检测子
Canny
Susan https://users.fmrib.ox.ac.uk/~steve/susan/susan/node8.html
待续